
 Español
Español English
English
Seguro que alguna vez has interactuado con una de ellas. Quizás le pediste a ChatGPT la mejor ruta para recorrer Madrid o viste cómo tu email autocompletaba tus frases con sentido. Sin ninguna duda, los Modelos de Lenguaje Grandes o LLMs (Large Language Models) han supuesto un cambio en las vidas de gran parte de la población mundial que hace unos años parecía de ciencia ficción. Esta tecnología ha llevado a una nueva revolución industrial transversal, saliendo de las fábricas u oficinas para llegar al bolsillo de mucha gente junto con sus infinitas posibilidades. A continuación, explicaremos la tecnología que ha permitido que todo esto sea posible.
¿Cómo entiende un ordenador una palabra?
Este fue uno de los principales retos del campo conocido como Procesamiento del Lenguaje Natural o NLP (Natural Language Processing). La traducción a reglas formales que pueda leer una máquina desde nuestro lenguaje es una tarea especialmente compleja. En los últimos años se han ido perfeccionando varias aproximaciones del ámbito de la Inteligencia Artificial como las Redes Neuronales para procesar una gran variedad de datos. Ahora bien, esta clase de métodos requiere de la digitalización de la información para poder procesarla. ¿Cómo se puede representar de forma numérica una palabra como por ejemplo “Pixel”? Una de las ideas que más fácilmente puede venir a la cabeza sería tratar a esta palabra como un conjunto de letras. Así, si se asigna a cada letra un número, podemos tener en un vector de números la palabra completa (como se puede ver en la Fig. 1).
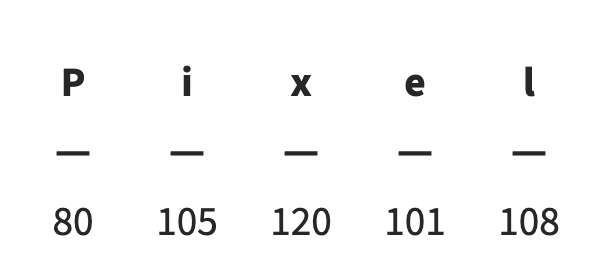
Fig 1. Representación en código ASCII de cada carácter de la palabra “pixel”.
Otra posibilidad es utilizar un diccionario persona-máquina con todas las palabras existentes ordenadas alfabéticamente y asignar un número identificativo a cada una. Por último, uno de los métodos utilizados por los modelos GPT es la división de cada palabra en subpalabras, creando una serie de bloques para conformar cada palabra. Cada una de estas posibilidades representa de distinta forma una palabra en unidades que en este campo se llaman tokens. Cada token tiene no solo un número, sino un vector numérico que permite identificarlo únicamente. Pero, ¿qué criterio se usa para asignar estos números a cada palabra?.
Uno de los enfoques con más sentido es que las palabras con más parecido semántico como “Pixel” y “Imagen” estén a menos distancia entre ellas que por ejemplo “Diabetes”. El motor que permite este paso son los Embeddings. Uno de los sistemas más utilizados para esto publicado por Google es Word2vec. Existen herramientas para visualizar en un espacio 2D o 3D los parecidos entre palabras o las palabras semánticamente más cercanas en este modelo como en esta Figura 2, donde se puede observar que “Pixel” está mucho más cerca de “Byte” o “Color” que de “Pimiento”.
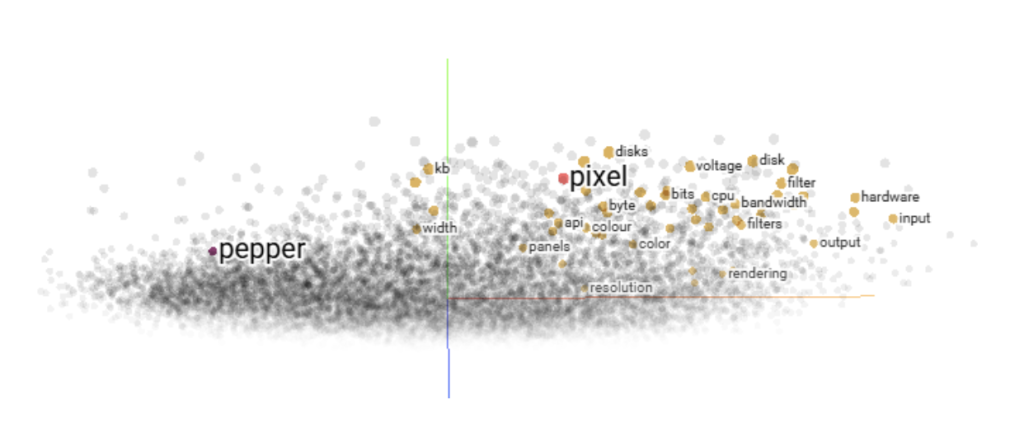
Fig 2. Representación gráfica tras un PCA de palabras por Word2vec.
De palabras a frases: El reto de memorizar
Ahora que podemos convertir palabras a datos, surge la duda de cómo poder hacer que se interpreten frases. Aquí, se planteó el uso de las Redes Neuronales Recurrentes (RNNs), que pueden recibir palabras secuencialmente para componer una frase. Esto hace que cada palabra no se entienda por sí sola sino acompañada de las palabras anteriores para dar sentido a la frase, dentro de un contexto. Este planteamiento funciona adecuadamente para frases cortas pero tiene un problema fundamental, la memoria. ¿Serías capaz de recordar la primera palabra que dijiste hoy?. Pues este tipo de redes sufren el mismo problema, y es que es complicado que las palabras mantengan la misma importancia en el momento en el que se reciben que pasado un tiempo.
En 2017 apareció una ingeniosa solución que no quedará en el olvido: El Transformer. Esta arquitectura de Red Neuronal proponía un método llamado atención. Con este sistema se consigue un valor más alto para los conceptos que son más relevantes para dar sentido a una frase y cómo se relacionan entre ellas. De esta forma se superó en gran medida el problema de memoria, ya que la distancia entre palabras no era un problema al prestar atención a las palabras más importantes para su comprensión. Si representamos gráficamente lo que pasa por un transformer se podría ver algo como la Figura 3, donde en la frase “Artificial Intelligence in Healthcare” se ve una relación muy alta entre las palabras “Intelligence” y “Healthcare”, indicando relación entre ellas al estar aplicada la inteligencia en este ámbito.
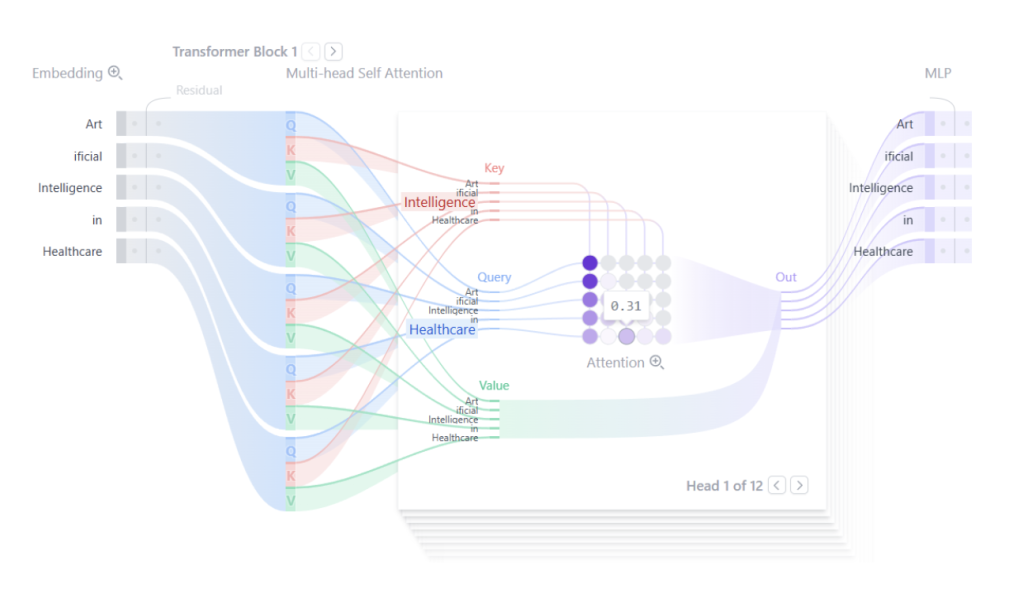
Fig 3. Representación gráfica del proceso de un transformer.
Enseñando a predecir palabras a partir de la Wikipedia
Hasta ahora hemos visto cómo se convierte una frase en algo que pueda leer un ordenador, pero falta el manual de instrucciones para poder entender. Se podría pensar que se requieren una gran cantidad de reglas gramaticales y formales para poder llegar a comprender una frase, pero esto necesitaría a mucha gente indicando a la máquina quién es el sujeto o cual es la acción para poder llegar a aprender.
La solución fue mucho más sencilla, y es que la gran especialidad para la que se entrenan estos modelos de lenguaje es autocompletar. Pensemos una frase, como por ejemplo “Transformando la gestión de residuos con IA”. Ahora, quita una de las palabras. ¿Podrías adivinar la palabra sin leerla?. Este es el planteamiento fundamental para entrenar este tipo de sistemas. Si realizas esto millones de veces extrayendo frases de una cantidad de texto masiva disponible en Internet como en la Wikipedia, libros, artículos o conversaciones se pueden llegar a entrenar modelos altamente complejos de gran precisión. De forma similar, si aplicamos esta predicción a la próxima palabra cada vez, se pueden ir formando frases en base a una petición del usuario. Por ejemplo en la Figura 4 se muestra la predicción para la frase “Cybersecurity for SMEs: Risks and How to Avoid Them” sin la última palabra. La palabra “Them” aparece la primera entre las opciones presentes.
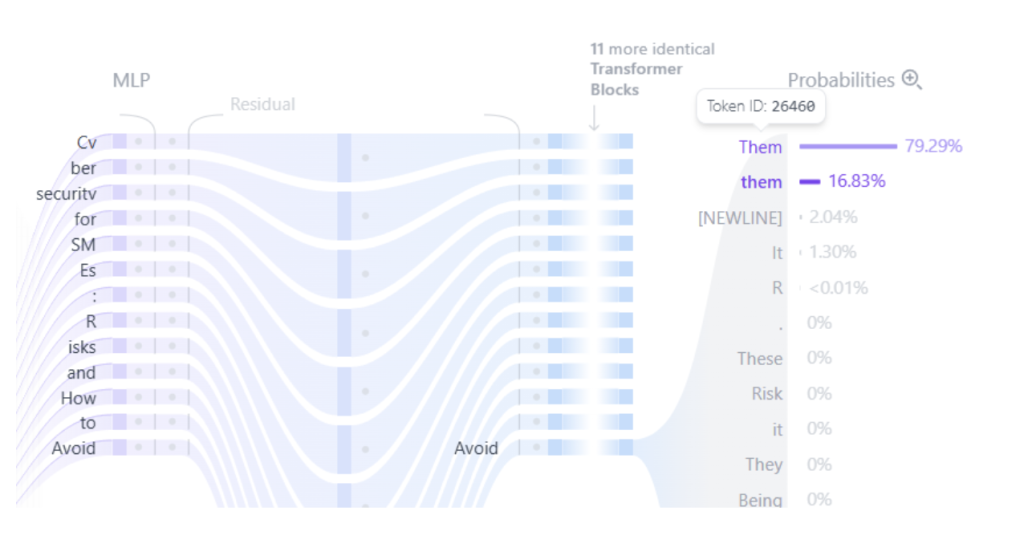
Fig 4. Resultado de la predicción de un transformer.
Presente y futuro en la convivencia con el nuevo copiloto de la mente humana
La IA generativa de texto ha dejado de ser un concepto de laboratorio para convertirse en una herramienta alcanzable para todos. El impacto más profundo de esta tecnología no reside en su capacidad para reemplazar tareas, sino para aumentar nuestras capacidades. Estamos entrando de lleno en la era del copiloto cognitivo.
Para un programador, es un asistente que depura código. Para un científico, un experto que resume investigaciones complejas. Para un artista, una fuente de inspiración que ayuda a superar el bloqueo creativo. Esta democratización de capacidades es la verdadera revolución: la potencia de un centro de datos se pone al servicio de la curiosidad de una persona, potenciando el taller de ideas que cada uno de nosotros tiene en su mente.
Sin embargo, este poderoso copiloto no está exento de turbulencias. Debemos ser conscientes de sus limitaciones para poder navegar con seguridad. La primera es el sesgo: los modelos aprenden de un reflejo de la humanidad depositado en Internet, y ese reflejo contiene nuestros prejuicios. Un LLM puede, por tanto, perpetuar estereotipos si no se guía y corrige. La segunda es la veracidad: un modelo no «sabe» que algo es cierto, solo sabe que es estadísticamente probable. Esto puede llevar a generar «alucinaciones», respuestas que suenan convincentes pero son falsas.
Esto nos obliga a redefinir nuestras propias habilidades. El futuro no pertenece a quien memoriza datos, sino a quien sabe formular las preguntas correctas, a quien aplica un juicio crítico a las respuestas de la IA y a quien aprende a colaborar creativamente con ella.
Quizás, la mejor forma de demostrar esta nueva simbiosis es con un ejercicio de transparencia. De hecho, la mayor parte de este apartado que acabas de leer ha sido redactado por un LLM.
Referencias
- Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). Attention Is All You Need.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space.
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training.
- Hochreiter, S., & Schmidhuber, J. (1997). Long Short-Term Memory.
- Alammar, J. (2018). The Illustrated Transformer.
- Christopher Olah. «Understanding LSTM Networks».
- Karpathy, A. (2015). The Unreasonable Effectiveness of Recurrent Neural Networks.